In this blog post I will outline the general approach to solve simple captchas, how to remove basic kinds of noise from an image and in the end how you can speed up and improve accuracy for the Tesseract OCR framework when used in Python. The task I tried to solve was detecting 100 of these captchas below in under 30 seconds.
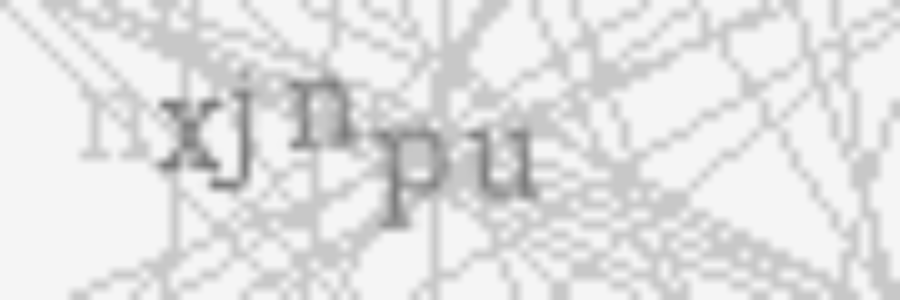
First lets try to outline the general approach to a captcha like this. Text can usually be deciphered very good with already existing OCR solutions like GOCR or Tesseract. Tesseract is currently developed by Google and has a big community, which is the reason I have chosen it for this post.
If we want to bring Tesseract to its full potential we need to ensure its input data is clean and readable. To make OCR detection as hard as possible, captcha creators try to insert as much noise as possible into an image. Possible in this case means, it is still readable and understandable by a human but should be hard to differentiate by a computer.
Now that we have a general idea what we want to achieve, so lets get started with the first step. We will use Python for our solver even though C would be faster, just because it is easier to understand and faster to write.
Removing noise from an image with Python can be done with the OpenCV library. It is a computer vision framework with a wide support of programming languages and very good documentation for Python. We will remove noise in three simple steps. First we want to load the image as an gray scale image and increase the image size, so that our filters we want to apply later, have impact on a lesser amount of pixels. Then we want to smoothen the image a little bit, which will give us better results in the last step, where we transform the different color tones of the image with a threshold into a binary representation.
Below you can see how every step impacts the input image.
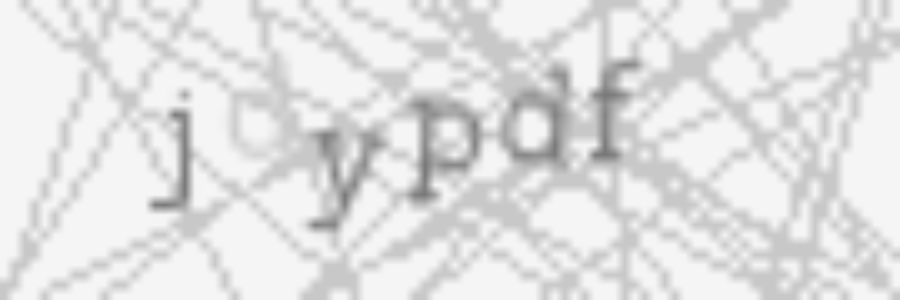

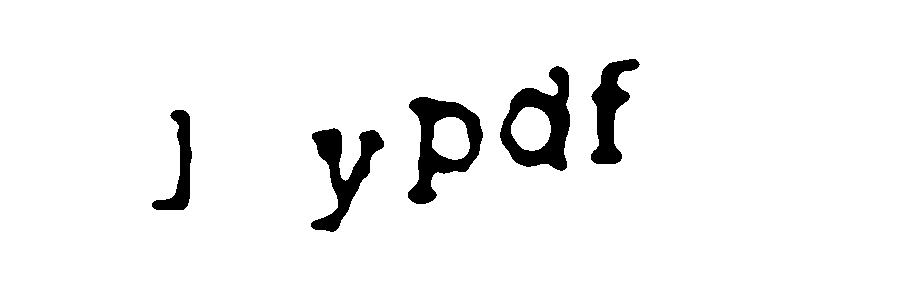
Now it is an easy thing to use tesseract on the resulting image. If we invoke it from the command line we see the results are not very good yet:
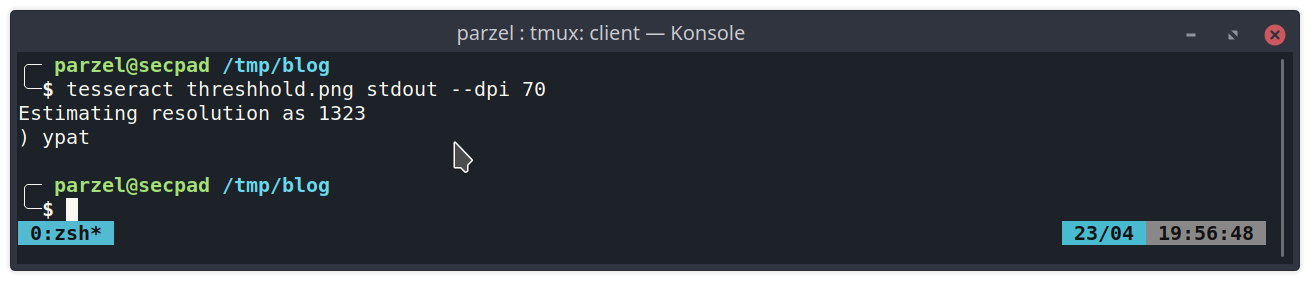
We can improve this by two simple tweaks. First we are going to specify the structure of the image by supplying the “–psm” parameter. As we can read up in the manual (man tesseract), number 8 will skip detection of the image struture and assume a single word.
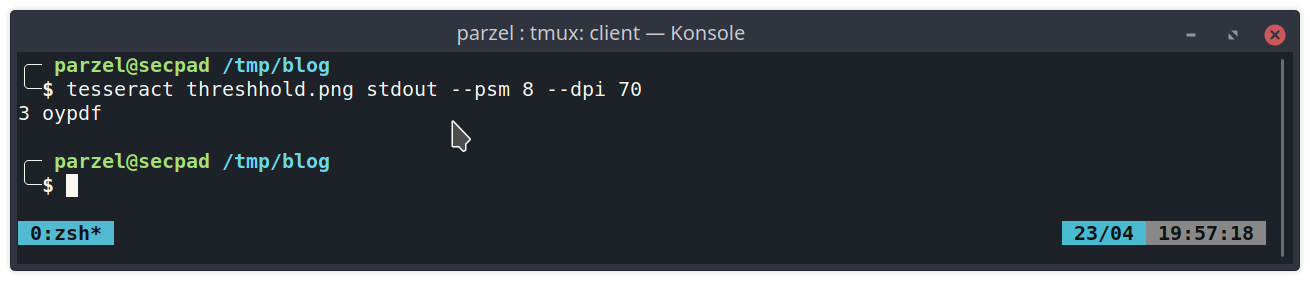
The second option we want to enable is the feature “tessedit_char_whitelist=…”. It allows us to restrict the detection to only recognize characters we whitelisted. This currently can only be used with the legacy version of tesseract, which is why we also force tesseract to use this engine with the “–oem 0” parameter.
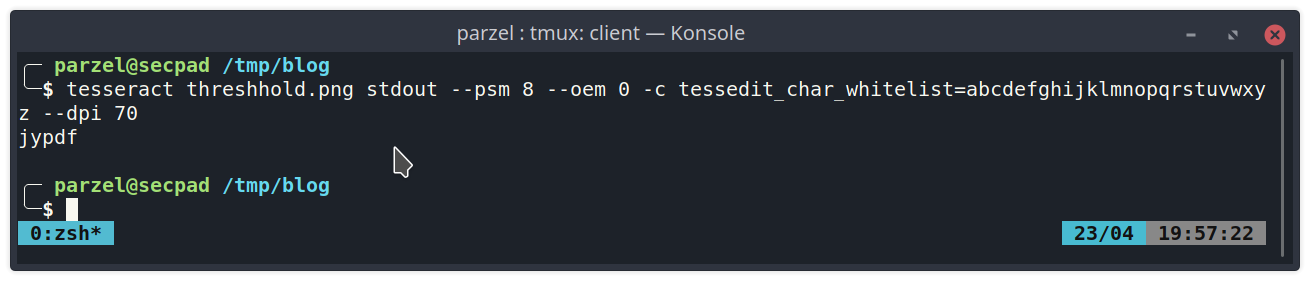
This looks pretty good now! Now we only need to find a Python plugin for handling tesseract. A quick search leads us to pytesseract. Pytesseract works really well and we can easily use it in our Python detection module. Lets see how it performs.

Here you can look up the source code for this basic steps:
import cv2
import os
import subprocess
import time
file_list = set(os.listdir("captchas"))
t_end = time.time() + 30
count = 0
while time.time() < t_end:
filename = f"captchas/{file_list.pop()}"
img = cv2.imread(filename, cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, None, fx=10, fy=10, interpolation=cv2.INTER_LINEAR)
img = cv2.medianBlur(img, 9)
th, img = cv2.threshold(img, 185, 255, cv2.THRESH_BINARY)
cv2.imwrite("image.png", img)
command = ['tesseract', 'image.png', 'stdout', '--psm', '8', '--oem', '0', '-c', 'tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyz', '--dpi', '70']
captcha_text = subprocess.check_output(command).decode().replace(" ", "").rstrip().lower()
os.rename(filename, f"captchas/{captcha_text}.png")
count += 1
print(f"Done. Solved {count} captchas in 30 seconds.")
That is way too slow for the goal we set ourselves! The slow speed of tesseract for recognizing only a few characters made me wonder if everthing is working to its optimum at this point. That was when I had a look at the source code of pytesseract and noticed that is basically just a wrapper for the command line tool of tesseract. By using the “time” command we can check how fast tesseract is for a single image. When I checked how fast it is for multiple images supplied at once I noticed the following:
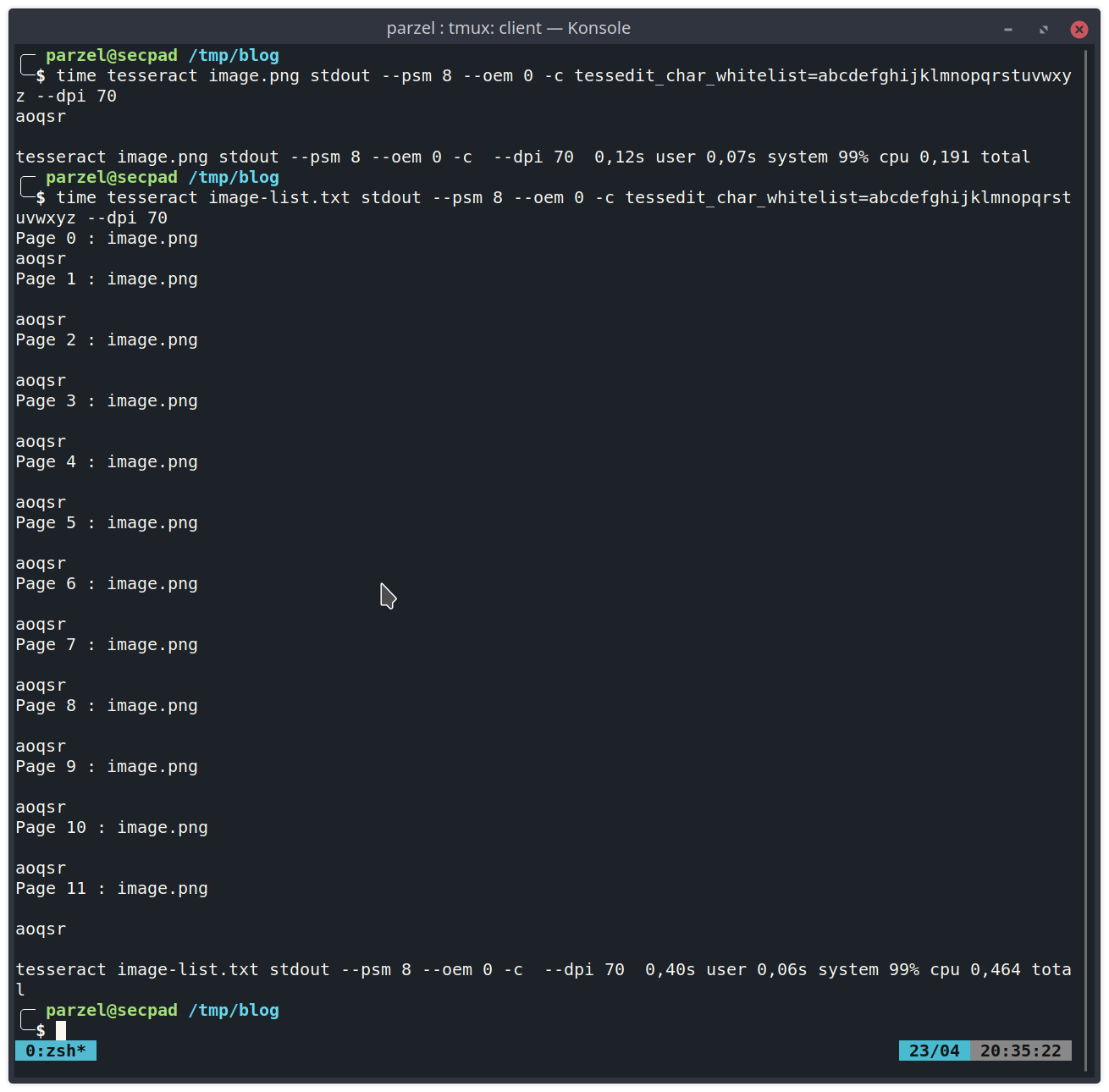
From this we can infer, that initializing tesseract needs a lot of time, while the actual detection is very fast. So I was looking for a faster alternative and found tesserocr. Tesserocr has one big advantage. It does not wrap the command line version of tesseract but instead uses libtesseract directly with Cython. By using this module we can avoid initializing the library over and over again. Lets modify our code and see how it performs.

And here is the source belonging to it:
import cv2
import os
import time
# https://github.com/sirfz/tesserocr/issues/165
import locale
locale.setlocale(locale.LC_ALL, 'C')
from tesserocr import PyTessBaseAPI, PSM, OEM
file_list = set(os.listdir("captchas"))
t_end = time.time() + 30
count = 0
with PyTessBaseAPI(psm=PSM.SINGLE_WORD, oem=OEM.TESSERACT_ONLY) as api:
api.SetVariable("tessedit_char_whitelist", "abcdefghijklmnopqrstuvwxyz")
while time.time() < t_end:
filename = f"captchas/{file_list.pop()}"
img = cv2.imread(filename, cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, None, fx=10, fy=10, interpolation=cv2.INTER_LINEAR)
img = cv2.medianBlur(img, 9)
th, img = cv2.threshold(img, 185, 255, cv2.THRESH_BINARY)
cv2.imwrite("image.png", img)
api.SetImageFile("image.png")
captcha_text = api.GetUTF8Text().replace(" ", "").rstrip().lower()
os.rename(filename, f"captchas/{captcha_text}.png")
count += 1
print(f"Done. Solved {count} captchas in 30 seconds.")
Perfect. So for all of you out there that need to do (faster) OCR detection in Python, maybe it is worth having a look at tesserocr instead of pytesser ;)
If you have comments or questions feel free to write me at twitter @parzel2